To sort, or not to sort ( Bubble, Quick )
Out there, there are tons of algorithms which are intended to fulfill one main goal, to sort. Nobody knows the exact number of how much algorithms of this kind exist and each of them overreaches the target in a different, more or less timesaving, way. What they still have in common is, that they take some bunch of data and bring it in a proper order.
As there exist so many sorting algorithms, this article is concerned with the analysis of two rather popular recursive ones. Especially aspects related to the performance and the operation principles of each algorithm will be examined.
Before you start reading I would strongly recommend you to get yourself a short introduction into Landau-notation or just the idea behind the use of Big O, 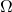 and
and 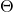 notation, as we will make use of the basics here.
notation, as we will make use of the basics here.
First of all I will introduce a subroutine used by each of the sorting algorithms, as it is used to swap the position of two elements within an Array or some similar constructed data structure.
SWAP(A : [1...n], i1, i2)
| # | Costs | Count | |
|---|---|---|---|
| 1. | tmp = A[i1] | 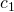 |
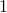 |
| 2. | A[i1] = A[i2] | 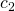 |
|
| 3. | A[i2] = tmp | 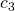 |
|
Summing up the costs of each line makes it possible to calculate the runtime for SWAP.
(1) 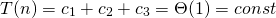
As the costs for each step of the routine are constant and each step is executed exactly 1 time, the total runtime of SWAP is asymptotically constant. I will refer to this section later on, when SWAP is used.
Bubble Sort
The first algorithm is one very simple and therefore kinda slow one, which just goes through a set of data and compares each member with its right neighbour. Dependent on their values, the higher valued participant moves right and swaps position with its less valued neighbour. If the order of the dataset changes during a run of Bubblesort the sorting will be repeated until the last run recognizes no more changes.
Knowing the principle of the algorithm makes it possible to describe it in a more analytical way, using Pseudo-Code. The following table displays the costs the execution of each line of Pseudo-Code requires and the times it will be executed on each call of the routine.
BUBBLESORT(A : [1...n], iteration : increments on each call)
| # | Costs | Count | ||
|---|---|---|---|---|
| BC | WC | |||
| 1. | changed = false | |
|
|
| 2. | for i = 1 to A.length – iteration inclusive | |
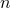 |
|
| 3. | if A[i] > A[i+1] | |
 |
|
| 4. | SWAP(A, i, i+1) | 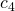 |
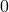 |
|
| 5. | changed = true | 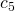 |
|
|
| 6. | if changed | 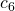 |
|
|
| 7. | BUBBLESORT(A, iteration+1) | |
|
|
Our next step is to predict the runtime of the routine. But first we have to face one remaining problem. Because of the conditional recursiveness of the algorithm, it is not possible to be 100% sure if the algorithm calls itself again. The solution for this problem is to observe the best and the worst case runtime separately, as done in the separate columns.
The best case occurs when the array is already sorted. In this case line 4., 5. and 7. will never be executed and it is possible to calculate the runtime easily, because the total runtime equals the runtime of one run.
![\[T(n) = c_1 + c_2 \cdot n + c_3 \cdot (n-1) + c_6\]](./sorting-analysis-bubble-quick_files/quicklatex.com-6e95f562e46b0e13f2573ab25489b72c_l3.png)
![\[T(n) = n \cdot (c_2 + c_3) + c_1 + c_6 - c_3\]](./sorting-analysis-bubble-quick_files/quicklatex.com-541362f72f1af5991f29d36cb3d69add_l3.png)
![\[\underline{T(n) = \Theta(n)}\]](./sorting-analysis-bubble-quick_files/quicklatex.com-cf4f8deb3ac0c5c2a2edce6ff1744017_l3.png)
While the runtime of the best case was easy to calculate, it turns out that, the worst case scenario is far more complicated to analyse. This scenario appears when the array is in reverse order.
Taking a look at the first 6 lines allows us to predict the non-recursive part of the runtime in the same way as used for the best case runtime.
![\[c_1 + n \cdot c_2 + (n-1) \cdot (c_3 + c_4 + c_5) + c_6 + c_7 =\]](./sorting-analysis-bubble-quick_files/quicklatex.com-1b54a6e2f8ead8ef47b4203bc910387b_l3.png)
![\[= n \cdot (c_2 + c_3 + c_4 + c_5) + c_1 + c_6 + c_7 - (c_3 + c_4 + c_5) =\]](./sorting-analysis-bubble-quick_files/quicklatex.com-78854be8cd6ea8d4ab696d5dcb7771b7_l3.png)
![\[= \underline{\Theta(n)}\]](./sorting-analysis-bubble-quick_files/quicklatex.com-198f68945e9f3948d5b5d08521fe0573_l3.png)
But as the routine calls itself again and again in line 7, we have to solve the following recursion equation in order to define a total runtime for the worst case scenario.
(2) 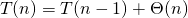
While the first part was just the sum of all costs times their occurences, the solution for the recursive part of the equation is a little bit trickier to find.
We have to imagine a recursion tree of levels, with a runtime of 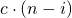 on the ith level, for all
on the ith level, for all 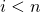 . So we get the total runtime by summing up every levels runtime, multiplying the result with the height of the tree.
. So we get the total runtime by summing up every levels runtime, multiplying the result with the height of the tree.
(3) 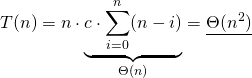
Putting the results for both extreme cases together, makes it possible to narrow the runtime of BUBBLESORT for input in any order.
![\[\underline{\underline{T(n)=\Omega(n) \cap \mathcal{O}(n^2)}}\]](./sorting-analysis-bubble-quick_files/quicklatex.com-a4e1571c830f0a70c857b409f8f56a3e_l3.png)
Quick Sort
Bubblesort is a nice example to get into sorting algorithms, but actually it is a little bit boring. So you may be glad to read that, we now attend to one more sophisticated exemplar, the Quicksort.
Quicksort basically runs through 4 steps.
- Pick a pivot element out of the input.
- Find one element less than the pivot element iterating from the left and one with a higher value starting from the right.
- Swap the two elements.
- Split the input in two parts and do the whole thing again using them as the input, using the pivot elements correct position as the delimiter.
As you can see, the principle of Quicksort is not very difficult to get. The only opportunity to make it a bit more fascinating, is the way you choose the pivot element. It turns out that, statistically it does not matter which element you take, but you have to keep in mind which one you chose, because it could affect the implementation.
I will use the element in the center of the input as the pivot element, also we have to know that Quicksort sorts in-place, i.e. there will be just the original input and no copy of it, thus the input will not have to be merged again after the sorting is done. As the sorting will be done in-place we need to delimit the part of the input the routine is currently working on in another way. We do this by requiring additional input, the two delimiting indices first and last. This time we can not use the size of the input to calculate the count each line is executed, so we have to definie one auxiliary variable to obtain the size of the currently processed part of the input.
![\[n:=(last-first)+1\]](./sorting-analysis-bubble-quick_files/quicklatex.com-ecbc29e0381ec2aa65991db2e1ff3bbf_l3.png)
Now we have enough information to define the whole thing in pseudo code and to predict a significant runtime for it.
QUICKSORT(A : [1...m], first, last)
| # | Costs | Count | ||
|---|---|---|---|---|
| BC | WC | |||
| 1. | if first < last | |
|
|
| 2. | pivot = A[(last + first) / 2] | |
|
|
| 3. | i = first | |
|
|
| 4. | j = last | |
|
|
| 5. | while i ≤ j | |
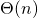 |
|
| 6. | while A[i] < pivot | |
||
| 7. | i = i + 1 | 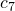 |
||
| 8. | while A[j] > pivot | 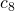 |
||
| 9. | j = j – 1 | 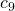 |
||
| 10. | if i ≤ j | 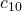 |
||
| 11. | SWAP(A, i+ +, j- -) | 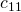 |
||
| 12. | QUICKSORT[A, first, i - 1] | |
||
| 13. | QUICKSORT[A, i, last] | |
||
Separating the analysis into cases makes it again possible to limit the possible runtime for any input. As both extreme cases occur for various inputs and the lines 5 to 11 are executed at a max of a multiple of linear , it suffices to say that, those lines are times executed. The interesting part happens in the lines 12 and 13 where the input is separated. Thus the runtime majorly depends on the size of each separated part.
At first we observe the best case, which appears when the pivot element is already on its correct position and the input is splitted into two parts of equal size. Because Quicksort is recursive, first of all we have to calculate the non-recursive required amount of runtime, which is needed to sort the currently processed part of the input.
![\[c_1+c_2+c_3+c_4+\Theta(n)\cdot(c_5+c_6+c_7+c_8+c_9+c_{10}+c_{11}) =\]](./sorting-analysis-bubble-quick_files/quicklatex.com-de9f3dc9484b53da748d3ad742cd4280_l3.png)
![\[ = \underline{\Theta(n)} \]](./sorting-analysis-bubble-quick_files/quicklatex.com-13ede6c85dddd857c32a479967c7f8e6_l3.png)
This gives us the recursion equation for the best case.
(4) 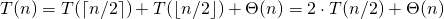
As the equation matches the pattern 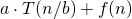 it is possible to apply the Mastermethod to solve the equation. Drawing the recursion tree would be a similarly easy way to resolve the equation.
it is possible to apply the Mastermethod to solve the equation. Drawing the recursion tree would be a similarly easy way to resolve the equation.
![\[a:=2, b:=2, f(n) = \Theta(n)\]](./sorting-analysis-bubble-quick_files/quicklatex.com-834e21c6af5604b13efdcdf54f1e00e1_l3.png)
![\[n^{\log_ba} = n \stackrel{2. case}{\Longrightarrow} f(n) = \Theta(n^{\log_ba}) = \Theta(n)\]](./sorting-analysis-bubble-quick_files/quicklatex.com-d76a78709736087f7109a8b440ec4925_l3.png)
![\[\Rightarrow \underline{T(n) = \Theta(n \cdot \lg n)}\]](./sorting-analysis-bubble-quick_files/quicklatex.com-a950110cf1fb7ad2934a3e27bdcde482_l3.png)
While the best case occurs when the input is splitted into two parts of most balanced size, the worst case occurs when the size of each part is maximum unbalanced. In other words, when the size of the first part equals and the second part is empty.
As the non-recursive amount of runtime equals the one calculated for the best case, we get the following recursion equation for Quicksort in worst case.
(5) 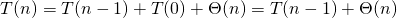
Now we have the same situation as in the worst case scenario of Bubble Sort. So we just have to use equation (3) to predict a runtime for the worst case scenario of Quicksort.
![\[\underline{T(n) = \Theta(n^2)}\]](./sorting-analysis-bubble-quick_files/quicklatex.com-0b1b834222a2bfc7168e0d204eb8d3b8_l3.png)
Summarizing our new insights, we are able to predict Quicksorts runtime in case of any input.
![\[\underline{\underline{T(n)=\Omega(n \cdot \lg n) \cap \mathcal{O}(n^2)}}\]](./sorting-analysis-bubble-quick_files/quicklatex.com-2b352d3dae569f86569397d93d90ab50_l3.png)
If you liked this article on the mathematical analysis of Quicksort and Bubblesort, I request you to support it by voting it up at Hacker News.